Spark笔记
为什么要出现RDD?
迭代算法(iterative algorithms)和交互式数据处理(interactive data mining tools)不够高效。
因为在需要数据复用(data reuse)的情况下,现有的手段是将中间数据写回磁盘,造成巨大的性能开销。
Resilient Distributed Datasets (RDDs)
RDDs are fault-tolerant, parallel data structures that let users explicitly persist intermediate results in memory, control their partitioning to optimize data placement, and manipulate them using a rich set of operators.
以上是论文中作者对于RDD的解释
- fault-tolerant
In-memory storage on clusters的抽象是细粒度的(fine-grained),比如kv-store,可以更新内存里的任意一条记录。但这就导致容错时需要备份数据和操作,而带宽相比内存是有限的。
因此RDD的设计是粗粒度的(coarse-grained)变换(transformations)。这样就可以只记录这些变换,而不用记录数据本身。
通过谱系图(lineage)这个DAG图进行操作,进行恢复。
- read-only
RDD是只读的,就是说不能改变已有的RDD中的内容。创建新RDD的操作就是变换(transformations)。
- persist & partition
explicitly persist 就是说用户可以显式指定RDD持久化到内存或是磁盘,因为用户可能在未来的计算中会用到这个RDD。Spark默认persist操作将RDD放在内存中,内存不够时会将RDD溢出到磁盘上,默认算法是LRU。
Spark Programming Interface
- transformations & actions
transformations是生成RDD,actions是进行的操作
Spark是lazy模式,就是说在action前并不进行实际计算。
lines = spark.textFile("hdfs://...")
errors = lines.filter(_.startsWith("ERROR"))
errors.persist()
// Return the time fields of errors mentioning
// HDFS as an array (assuming time is field
// number 3 in a tab-separated format):
errors.filter(_.contains("HDFS"))
.map(_.split(’\t’)(3))
.collect()
persist操作显式地将errors放在内存
如上图,在collect操作时真正进行计算,返回结果
注意,pipeline transformations中间结果并不保存
RDD优缺点
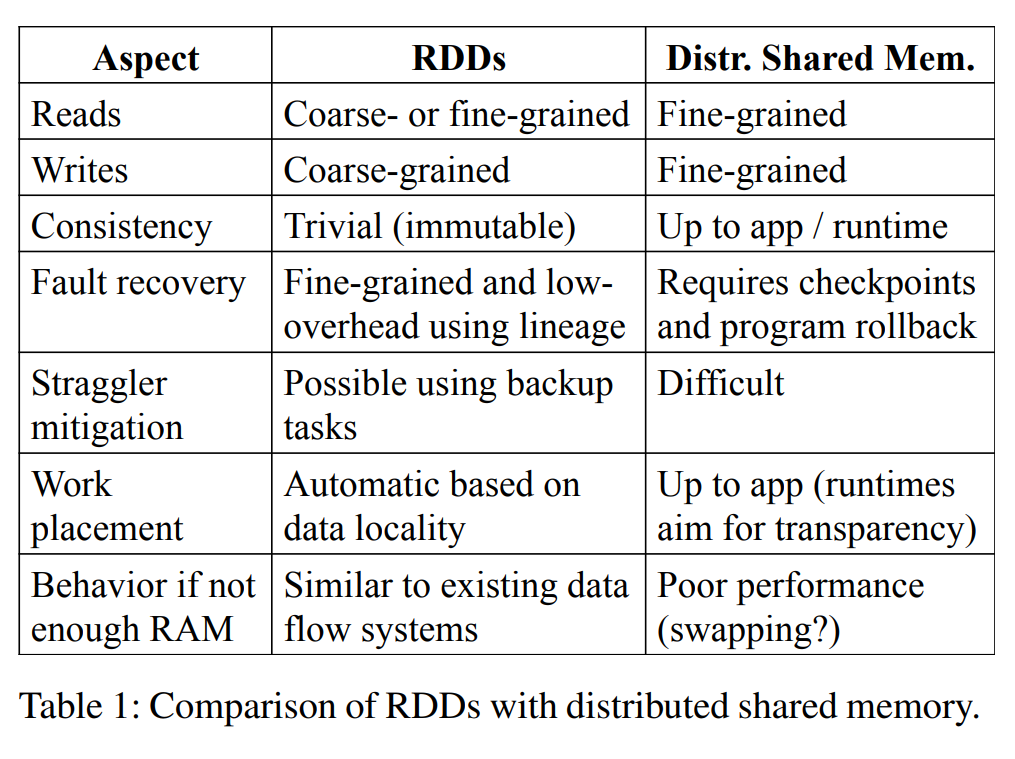
RDD用粗粒度的更新提升了容错的效率,能更好支持批处理计算,但对于细粒度操作不适合,比如爬虫。
Spark Programming Interface
RDD之间的依赖关系
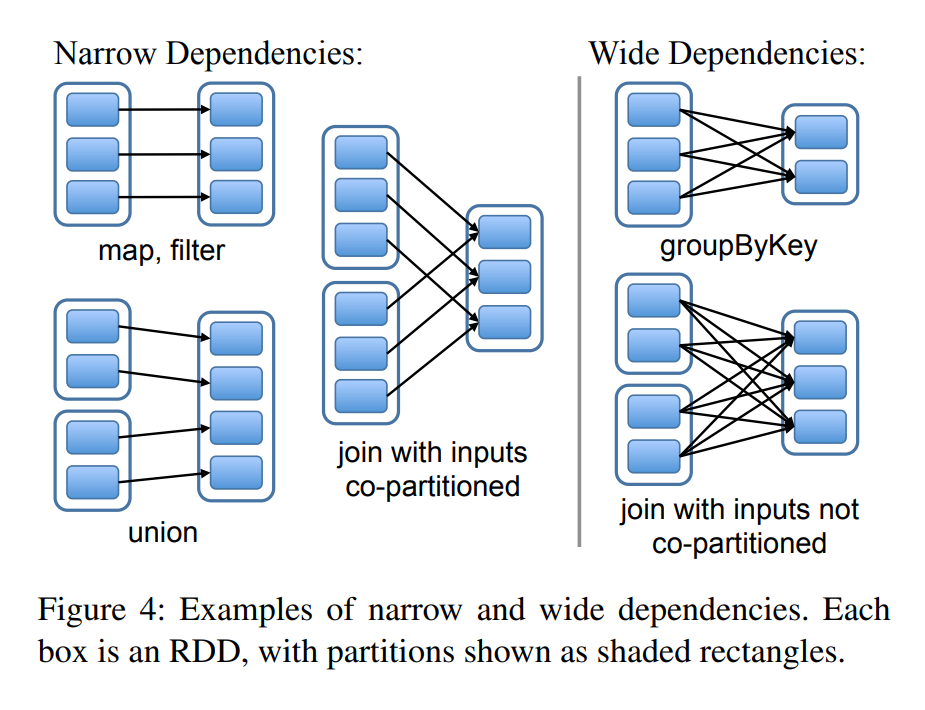
分为宽依赖和窄依赖
- narrow dependencies 父RDD最多被一个子RDD依赖
- wide dependencies 父RDD被多个子RDD依赖
区分的原因
- 流水线执行(pipelined execution):一个窄依赖的partition在完成一个算子时,不必等待其他分区,可以直接进行后续计算。而宽依赖需要等它所有父RDD计算完成后,才能进行下一步。
- 数据恢复:窄依赖恢复涉及到的父分区少,且可以并行恢复。宽依赖的恢复涉及到大量分区。
任务调度

-
当遇到action,调度器会根据谱系图生成包含stage的有向无环图。
- 每个stage都包含尽可能多的窄依赖操作(pipelined transformations with narrow dependencies)
- 调度器只要调度计算不在内存中的RDD即可
- 调度器根据数据的局部性调度任务。
- partition在某一结点的内存中,调度该任务到该节点
- partition在磁盘上,调度到preferred locations(比如HDFS file)